
Explanation of Research in Japanese
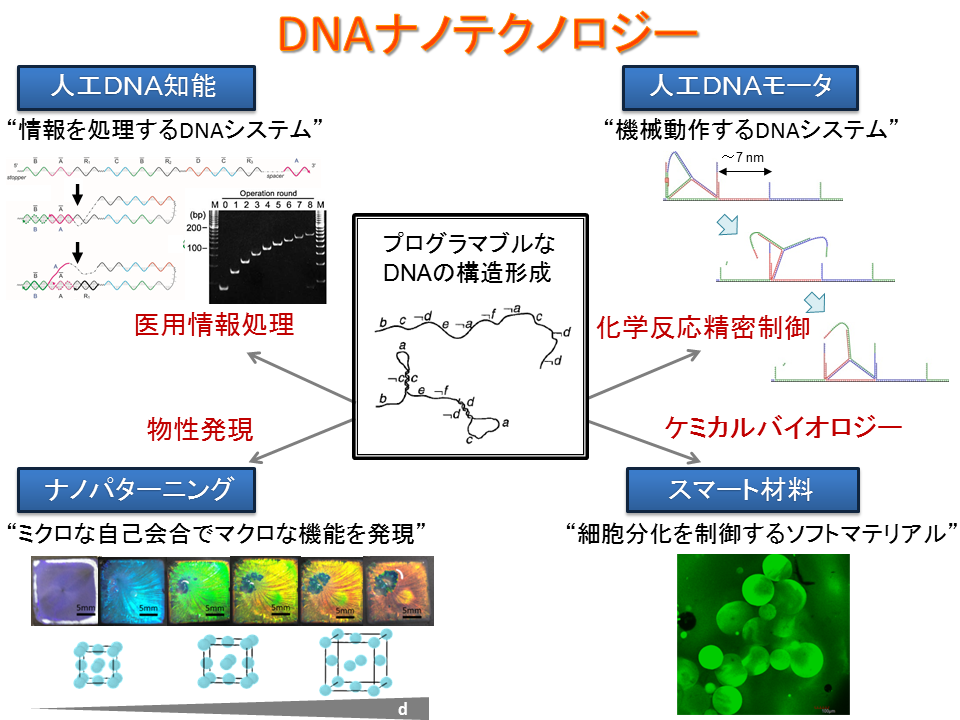
Introduction: DNA nanotechnology
1980年代に端を発する構造DNAナノテクノロジー研究は、2006年のDNAオリガミ研究を機に急速に発展しました。ナノメートル精度の自己会合をDNAの塩基配列で指定できる画期的な技術で、2020年現在も、より複雑で巨大な会合体の作成法などの報告が相次いでいます。
一方、DNAの自己会合を繰り返す反応をナノスケールの機械動作として利用するDNAナノマシン研究は、2000年に足がかり(toehold)配列を利用する配列特異的な鎖置換反応の考案により始まりましたが、その方向性や有用性は定まっていません。
また、1994年にDNA分子の自己会合を利用してランダムに解の候補を生成し、簡単なDNA実験で正解を探索するDNAコンピューティング研究が報告されました。これは人が操作する実験プロトコルによって情報処理のアルゴリズムを実装する研究ですが、当グループではDNAと酵素が行う多段階反応により分子がアルゴリズムを実装する自律的DNAコンピューティング反応を開発しました。
2010年頃までの重要研究マップ
※クリックすると拡大されます

当グループでは、熱力学的に最安定な構造を形成する構造DNAナノテクノロジーに対し、まだ科学的意義や実用性の見えていないDNAナノマシンやDNAコンピューティングといった、時間的に構造が変化する動的DNAナノテクノロジーに新たな発見をもたらし、生物学に活用する研究を行っています。
Past research by our group
2013年までの当グループの研究成果の概要
※クリックすると拡大されます
DNA-based Computing & DNA Nanomachines
【Backgrounds】
― DNAで情報を処理する
DNAはA、C、G、Tいずれかの塩基を含む4種のデオキシヌクレオチドが連なった直鎖状分子の総称です。DNA分子どうしのちがいはデオキシヌクレオチドの並び方のちがいですから、各DNA分子種は「GATTACA」といった塩基配列で表されます。たとえばヒトの1番染色体DNAは、およそ2億5千万塩基長の配列になります。また、AとT、GとCという対合規則にしたがって、DNAの相補的な塩基配列を持った部分どうしは結合して二重らせんを形成します。
規則的に結合するというDNAの性質を利用すると、計算(情報処理)を行うことができます。まず、電子コンピュータにならってDNAの塩基配列に意味を持たせます。電子コンピュータで使われているASCIIコードでは、「D」「N」「A」という3つのアルファベットは、{0, 1} の2進数でそれぞれ「100 0100」「100 1110」「100 0001」という配列と対応づけられています。電子コンピュータにとっては「100 0100 100 1110 100 0001」という配列が、「DNA」という文字列を意味します。DNAでも同じように考えると、「D」「N」「A」という3つのアルファベットをたとえば、「TTAGAC」「ATGTCC」「TGAGTG」という塩基配列とそれぞれ対応づけます。すると、「TTAGAC ATGTCC TGAGTG」という塩基配列が「DNA」という文字列を意味することになります。
それでは、『ある3文字の文字列「XXX」(X はアルファベット A ~ Z のいずれか)のなかに「D」が含まれているか?』という問題は、どのようにしたらDNAで解くことができるでしょうか。この問題は、文字列「XXX」を意味する「xxxxxx xxxxxx xxxxxx」(x は A、C、G、Tいずれかの塩基)という塩基配列のなかに、「D」を意味する「TTAGAC」という配列が含まれているかどうかを検証する問題です。DNAは相補配列どうしが結合するので、「TTAGAC」の相補配列である「GTCTAA」という配列を持った検証用DNAを投入し、この検証用DNAと結合したDNAが回収された場合はそのDNAの塩基配列は「TTAGAC」を含んでいる、つまりアルファベット「D」を含んでいる。回収されなかった場合は含んでいない、ということがわかります。
― in vitro Intelligenceに向けて
このように、DNAの塩基配列を文字列とみなし、遺伝子工学で用いられる様々な実験手法を用いてDNAを切ったりつなげたりして文字列を変換することで計算を行う「DNAコンピューティング」が、1994年のAdlemanによる実証実験を契機として盛んに研究されました。しかし、DNAコンピューティングではDNA分子は文字列の記録メディアに過ぎず、計算の各ステップは人間が行う実験操作で実現されます。そのため計算には、プログラムに相当する実験プロトコルを把握した人間と各種の実験機器を使用した操作を行う実験室が必要となります。そこで私たちは、1滴の溶液中で起こる分子反応で全ての計算プロセスを実現する「試験管内知能(in vitro Intelligence)」の研究に取り組んでいます。下記の反応を実現したほか、メチル化などのエピジェネティックな反応を利用する情報処理の検討も行っています。
・SAT Engine
― “DNAで計算する” から “DNAが計算する” へ
DNAが分子内で会合するヘアピン構造形成を利用して、1回のDNAの構造形成で多数の変数への真理値の割当に矛盾がないかを検証する充足可能性(Satisfiability: SAT)問題の解法を実現しました。これはSIMD (Single instruction, Multiple Data)な計算に相当します(Sakamoto, et al., Science, 2000)。
・Whiplash PCR
― 1分子のDNAが多段階に計算する
DNAのヘアピン構造形成とDNAポリメラーゼによる伸長反応を利用して、1回の反応で多段階の情報処理を実行する反応を開発し、有向ハミルトン経路問題(Directed Hamiltonian Path Problem: DHPP)をはじめ様々な問題の解法が実行できる状態機械を開発しました。これはMIMD (Multiple instruction, Multiple Data)な計算を実行した、現在も世界唯一の反応系です(Komiya, et al., BioSystems, 2006)。
DNAコンピューティングを生物学に活用するため、溶液中の核酸分子群をシグナルとして受け取り、37℃の温度条件で動作する機構に改変した反応系も開発しました(Komiya, et al., Natural Computing, 2010)。測定機器を使わずに分子が遺伝子プロファイリングする細胞機能の制御に利用します。
・Temperature-Controlled DNA Nanomachine
― 特定の温度帯でのみで動作するDNAナノマシン
配列特異的な結合によるDNAナノ構造は通常、低温で形成され、高温で融解します。これは最安定な構造形成の挙動ですが、準安定な構造形成は低温と高温のあいだの特定の温度で形成効率が最大になります。この挙動を定量的に予測する統計熱力学モデルを作成し、DNAが予測通り振る舞うことを実証しました(Komiya, et al., Nucleic Acids Resarch, 2010)。酵素反応を制御するDNAナノマシンとして利用します。
Links

resize.jpeg "RInCA「分子ロボRRI」")



